FAQs zum PIO-ULB Editor
Diese Seite geht auf grundlegende Fragen bezüglich dem PIO-ULB Standard, der Funktionsweise des PIO-ULB Editors und dessen Softwarearchitektur ein. Da wir im Projektverlauf immer wieder von Kooperationspartnern, Softwareherstellern oder anderen interessierten Personen ähnliche Fragen gestellt bekamen, entschlossen wir uns diese FAQ-Seite zu veröffentlichen.
Stand der Website: 16.04.2025
Version der PIO-ULB Spezifikation: 1.0.0
1. Allgemeine Fragen zum PIO-ULB Editor:
1.1 Was ist ein PIO-ULB?
Um die Digitalisierung im Gesundheitssektor voranzutreiben, hat das Bundesministerium für Gesundheit (BMG) die Entwicklung von Medizinischen Informationsobjekten (MIOs) gesetzlich beauftragt. Die mio42 GmbH entwickelt diese Informationsobjekte in Zusammenarbeit mit der Kassenärztlichen Bundesvereinigung (KBV).
MIOs sind digitale Informationsbausteine, die medizinische Daten enthalten und zukünftig interoperabel von allen Systemen im Gesundheitswesen gelesen und verarbeitet werden können. Dies geschieht auf Basis internationaler Standards, um den reibungslosen Austausch der Daten zwischen den Akteuren im Gesundheitswesen zu gewährleisten – unabhängig vom verwendeten Softwaresystem.
Auch rein pflegerische Dokumente sollen zukünftig in Form von MIOs digitalisiert werden. Hier wird der Begriff Pflege-Informationsobjekt (PIO) verwendet.
Beispiele für fertig spezifizierte MIOs:
- Impfpass
- Medikationsplan
- Mutterpass
- Zahnärztliches Bonusheft
Beispiele für PIOs:
- Überleitungsbogen (festgelegt / fertig spezifiziert)
- Überleitungsbogen Chronische Wunde (Entwicklung aktuell pausiert)
Der PIO-Überleitungsbogen (PIO-ULB) ist das erste Informationsobjekt für die Pflege und bildet einen standardisierten Pflegeüberleitungsbogen ab. Die PIO-ULB Spezifikation wurde im Dezember 2022 final veröffentlicht. Somit ist der PIO-ULB das erste standardisierte Pflegedokument im Rahmen der Pflegedokumentation. Der "PIO Überleitungsbogen Chronische Wunde" ist ein weiteres wichtiges professionsübergreifendes Dokument, dessen Weiterentwicklung jedoch derzeit pausiert.
MIOs und PIOs sind XML-Dateien, welche medizinische und pflegerische Daten in standardisierter sowie maschinenlesbarer Form speichern. Sie basieren auf dem internationalen Standard FHIR (Fast Healthcare Interoperability Resources), welcher strukturiert medizinische Daten abbildet. Die Informationsobjekte sollen zukünftig in der elektronischen Patientenakte (ePA) gespeichert werden.
Seit der Festlegung des PIO-ULBs im Dezember 2022 ruht die Weiterführung, da er aktuell nicht in der Roadmap der ePA berücksichtigt ist. Änderungen durch das Digital-Gesetz (DigiG) sehen ab 2025 vor, dass mio42-Aktivitäten einen Auftrag des Kompetenzzentrum für Interoperabilität im Gesundheitswesen (KIG) benötigen. Pflege-Themen, wie der PIO-ULB, sind jedoch momentan nicht für die ePA vorgesehen.
Weiterführende Informationen:
- Infos zur Mio42 GmbH [Stand 08.04.2025]
- Infos zum PIO-ULB Standard [Stand 08.04.2025]
1.2 Warum wurde der PIO-ULB Editor entwickelt und was kann der Editor?
Das Teilprojekt 3 des Forschungsverbundes Care Regio hat sich zum Ziel gesetzt, den Datenübertragungsprozess von pflegerelevanten Patientendaten im Rahmen einer Patientenüberleitung von einer Pflegeeinrichtung in eine andere zu digitalisieren und zu optimieren. In diesem Teilprojekt arbeiten die Technische Hochschule Augsburg, das Universitätsklinikum Augsburg und zwei kooperierenden Pflegeeinrichtungen in Augsburg zusammen an der Konzipierung und Implementierung eines PIO-ULB Editors. Unser Editor ist eine der ersten nutzbaren Implementierungen des PIO-ULB Standards überhaupt.
Der Editor soll PIO-ULB Dateien standardkonform generieren und importieren können. Ein nutzerfreundliches User Interface erleichtert dem Pflegepersonal das arbeiten mit dem neuen Standard. Beim Import von PIO-ULB Dateien wird die Datei auf Konformität zum Standard validiert.
Weiterführende Informationen:
- Website Care Regio [Stand 08.04.2025]
- Care Regio - Hochschule Augsburg [Stand 08.04.2025]
- Universitätsklinikum Augsburg [Stand 08.04.2025]
1.3 Wo kann ich den PIO-Editor testen?
Der PIO-ULB Editor kann auf unserer Website kostenfrei genutzt werden (siehe hier). Nach einer Anmeldung mittels Vor- und Nachnamen, können beliebige standardkonforme XML-Dateien (= PIOs) generiert und wieder importiert werden. Der angegebene Name wird automatisch als Autor im PIO-ULB hinterlegt.
Die eingetragenen Daten werden nur für die aktive Nutzungsdauer gespeichert und anschließend sofort gelöscht. Es gibt also keine Möglichkeit, Daten nach dem Schließen des Browserfensters oder einem Logout wiederherzustellen.

Unsere Website erfüllt die Datenschutzanforderungen für Gesundheitsdaten nicht. Daher bitte keine realen Patientendaten auf unserer Website eintragen.
1.4 Wo kann ich den Quellcode des PIO-ULB Editors einsehen?
Der gesamte Quellcode des PIO-ULB Editors ist auf GitHub veröffentlicht und wird auf dem aktuellen Stand gehalten (siehe hier, Stand 08.04.2025).
Weitere Informationen zur Softwarearchitektur sind unter Punkt 3 zu finden.
1.5 Darf ich den Quellcode des PIO-ULB Editors für meine eigenen Projekte verwenden?
Da alle Ergebnisse aus dem Care Regio Forschungsprojekt open source zur Verfügung stehen sollen, kann auch der Quellcode des PIO-ULB Editors für andere (auch kommerzielle) Projekte genutzt werden. Unser PIO-ULB Editor wurde im Dezember 2023 unter der Apache 2.0 Lizenz veröffentlicht.
1.6 Wie kann ich den PIO-ULB Editor auf meinem lokalen Computer zum Laufen bringen?
Alle Komponenten des PIO-ULB Editors sind dockerisiert und können wie ein üblicher Docker Container gestartet werden. Folgende Komponenten / Docker Container müssen gestartet werden, damit der PIO-ULB Editor auf dem lokalen Computer funktioniert:
- Frontend
- Backend inkl. mongoDB Datenbank
- Validator
Eine sehr komfortable Möglichkeit den PIO-ULB Editor auf einem lokalen Computer zu starten ist das PIO_Editor Repository auf GitHub (siehe 1.4). Hier werden alle nötigen Docker Container automatisch heruntergeladen und gestartet. Die Installationsanleitung unter Windows ist in der README-Datei des Repositories zu finden und wird in Folgendem schrittweise erklärt:
- „PIO_Editor“ Repository von GitHub downloaden
- Docker Engine auf dem Computer installieren und starten
- Die Datei „docker-compose.yml“ aus dem „PIO_Editor“ Repository mit Hilfe des Terminalbefehls docker compose up -d ausführen
- Alle nötigen Docker Container werden automatisch heruntergeladen und gestartet (Internetverbindung benötigt)
- Der PIO-ULB Editor („localVersion“) ist nun unter der URL http://localhost im Browser erreichbar
Der PIO-ULB Editor wird über das "PIO_Editor" Repository in der "localVersion" gestartet (siehe 3.4). Um den PIO-ULB Editor in der „webVersion“ zu starten, müssen zwei Zeilen der „docker-compose.yml“ Datei angepasst werden. In Zeile 4 und 19 muss der Image-Tag „:localVersion“ in „:webVersion“ umbenannt werden.
Durch die Ausführung des "PIO-Editor" Repositories werden insgesamt fünf Docker Images heruntergeladen und gestartet. Das Docker Image für das Frontend, das Backend und den Validator Service werden von unserer GitHub Seite heruntergeladen. Das Image für die mongoDB Datenbank wird von Docker-Hub gezogen. Das fünfte Docker Image ist ein NGINX-Server, welches ebenfalls von Docker-Hub heruntergeladen wird. Dieser Server fungiert als Reverse Proxy für alle Backend Anfragen. Das Meta- und FHIR-Repository wird auf unserer GitHub Seite als NPM-Package bereitgestellt und automatisch installiert. Mehr Informationen zur Softwarearchitektur sind unter Punkt 3 zu finden. Folgende Abbildung zeigt die Systemarchitektur des PIO-ULB Editors, wobei der NGINX-Server nicht dargestellt ist:
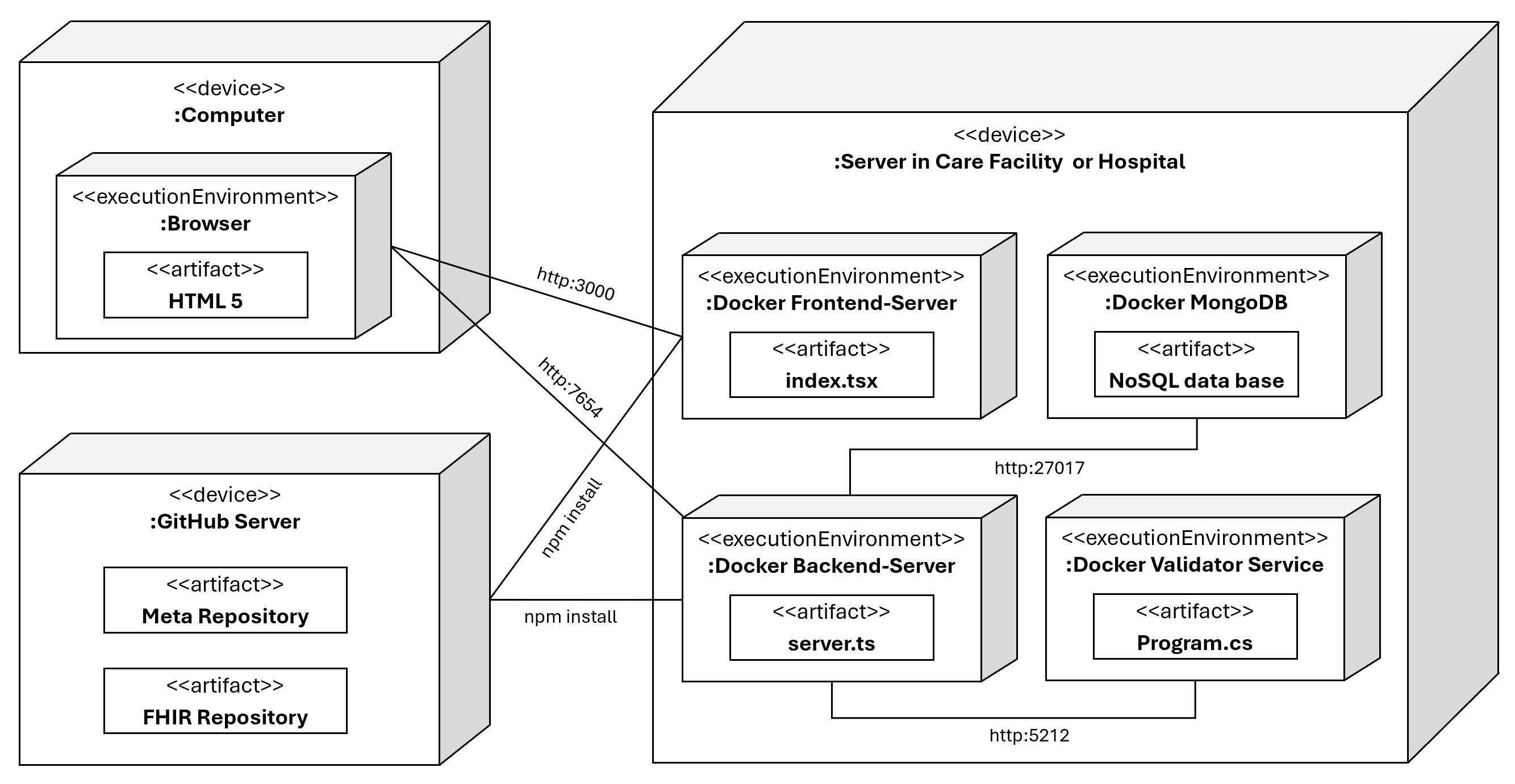
Abbildung: UML-Verteilungsdiagramm des PIO-ULB Editors im lokalen Netzwerk einer Einrichtung
Sollten die Softwarekomponenten ohne Docker gebaut werden, so ist der Build auf Linux Systemen lauffähig.

Wird der PIO-ULB Editor lokal gestartet, dürfen reale Patientendaten in den Editor eingegeben werden, solange der lokale Computer die Datenschutzanforderungen für Patientendaten erfüllt.
1.7 Bildet der PIO-ULB Editor den gesamten PIO-ULB Standard ab?
Nein, der PIO-ULB Editor implementiert ungefähr nur zwei Drittel des gesamten ULB-Spezifikationsumfangs. Wir haben ein eigenes Dokument verfasst, in dem alle Abweichungen des PIO-ULB Editors zum spezifizierten Standard beschrieben sind. Dieses Dokument kann im PIO-ULB Editor selbst heruntergeladen werden (siehe sich automatisch öffnender Disclaimer beim erstmaligen Starten des Editors).
Alternativ kann das Dokument auch hier heruntergeladen werden: PIOEditorLimitationen.pdf
Grund für die Reduzierung des Umfangs waren knappe Ressourcen im Forschungsprojekt sowie die von Pflegekräften bestätigte Erkenntnis, dass die PIO-ULB Spezifikation zu komplex und zu umfangreich für den alltäglichen Gebrauch ist.
Daten, die der PIO-ULB Editor nicht unterstützt, können vom Nutzer nicht eingegeben und exportiert werden, da die Benutzeroberfläche kein entsprechendes Eingabeelement bereitstellt. Sollte ein PIO-ULB importiert werden, welches nicht unterstützte Informationen enthält, werden diese Daten in einem dritten Reiter angezeigt (siehe Abbildung). Somit können die Informationen wenigstens gelesen werden, ein Editieren oder ein erneuter Export ist für diese Daten jedoch nicht möglich.
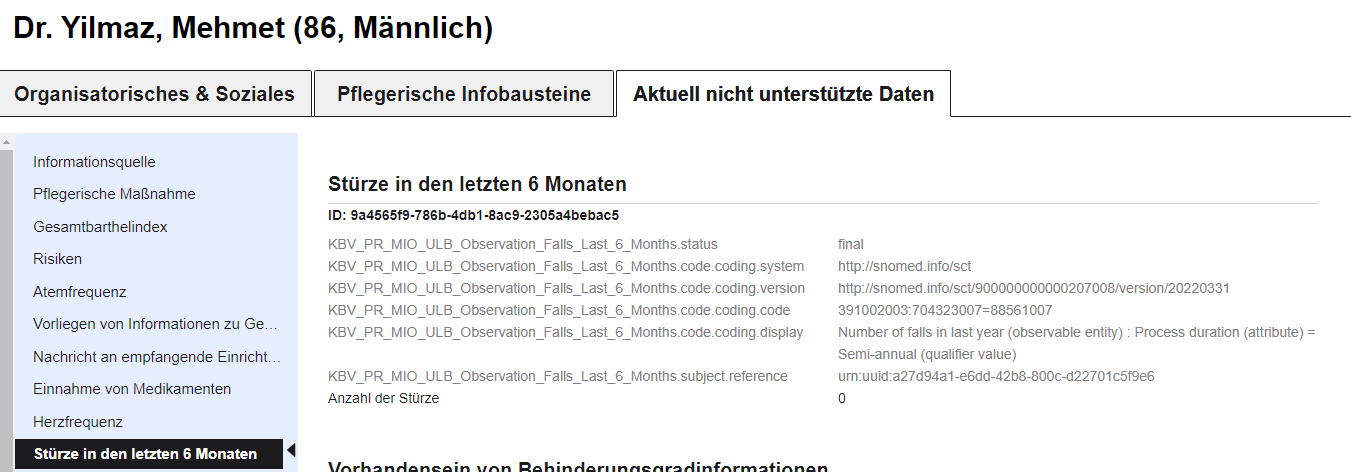
Abbildung: Aktiver dritter Reiter im PIO-ULB Editor, welcher Daten des nicht unterstützten drittel der PIO-ULB Spezifikation unstrukturiert anzeigt.
1.8 Ist der PIO-ULB Editor für den Gebrauch im pflegerischen Alltag vorgesehen?
Nein, der PIO-ULB Editor ist ein Prototyp, der nicht für den pflegerischen Alltag gedacht und zertifiziert ist. Im Wesentlichen soll dieser Prototyp eine Diskussionsgrundlage durch die nutzerverständliche Visualisierung des PIO-ULB Standards schaffen sowie für weiterführende Implementierungen (z.B. durch Primärsystemhersteller) als Vorlage dienen.
1.9 Kann der PIO-ULB Editor die generierte Datei auch gleich an die aufnehmende Pflegeeinrichtung verschicken?
Nein! Durch den Klick auf den “Export” Button im PIO-ULB Editor werden alle eingegebenen Daten als standardkonforme XML-Datei (= PIO) im Downloadmanager des Browsers heruntergeladen. Diese nun lokal verfügbare Datei kann mithilfe anderer Tools an die Einrichtung, die den Patienten empfängt, vorab gesendet werden.
Im Rahmen unseres Forschungsprojektes haben wir die XML-Datei mit Hilfe des KIM-Services versendet. KIM (Kommunikation im Medizinwesen) ist ein E-Mail-Dienst für Gesundheitseinrichtungen, mit dem Patientendaten datenschutzkonform verschickt werden können. Alternativ kann die XML-Datei in die persönliche elektronische Patientenakte des Patienten hochgeladen werden. Anschließend kann die empfangende Einrichtung die Datei aus der elektronischen Patientenakte herunterladen. Für beide Übertragungsszenarien muss sowohl die sendende als auch die empfangende Einrichtung an die Telematikinfrastruktur (sicheres Netzwerk zum Austausch sensibler Gesundheitsdaten in Deutschland) angeschlossen sein.
Weiterführende Informationen:
- Infos zum KIM-Service [Stand 08.04.2025]
- Infos zur elektonischen Patientenakte [Stand 08.04.2025]
1.10 Besitzt der PIO-Editor eine Schnittstelle zu Primärsystemen?
Nein! Eine Schnittstelle zu KIS-Systemen (Krankenhausinformationssystem) oder anderen Pflegedokumentationssystemen ist wünschenswert, um den Erstellungsprozess des PIO-Überleitungsbogens zu automatisieren, kann aber im Rahmen des Forschungsprojektes nicht realisiert werden. Hier müssen die Primärsystemhersteller selbst tätig werden und ihre interne Datenstruktur auf den PIO-ULB mappen. Eine fehlende gesetzliche Verpflichtung zur Umsetzung des PIO-ULBs, der aktuell sehr geringe Verbreitungsgrad des PIO-ULBs und die hohe Komplexität des PIO-ULB Standards lassen Primärsystemhersteller zögern, eine PIO-ULB Schnittstelle zu implementieren.
Aktuell muss das Pflegefachpersonal die Patientendaten manuell in unseren PIO-ULB Editor eingeben. Für einen hochgradig automatisierten und digitalisierten Datenüberleitungsprozess ist es unverzichtbar, dass Primärsystemhersteller den PIO-ULB Standard unterstützen. Deshalb versuchen wir im Rahmen des Forschungsprojektes, diese Thematik an verschiedene Softwarehersteller heranzutragen und bieten unsere Unterstützung an.
1.11 Welche Dateiformate kann der PIO-ULB Editor exportieren?
Der PIO-ULB Editor kann eine standardkonforme XML-Datei sowie eine PDF-Datei exportieren. Beim Klick auf "Export" kann sich der Nutzer für eine der beiden Varianten entscheiden (siehe Abbildung):
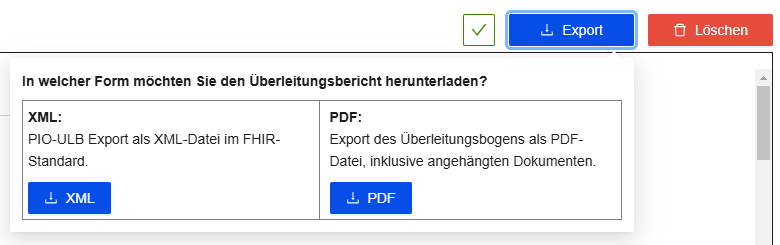
Abbildung: Unterstützte Dateiformate beim Exportieren der Daten
Der PDF-Export bildet alle Eingabefelder aus der Benutzeroberfläche des Editors ab. Alle Dateien, die ergänzend zu den Patientendaten im Editor hochgeladen wurden (z.B. Patientenverfügung, Medikationsplan oder andere wichtige Dokumente), werden der PDF-Datei beim Export angehängt. Zusätzlich wird ein Signaturfeld am Ende der PDF-Datei generiert. Hier können Pflegefachpersonen unterschreiben, falls die PDF-Datei zu Archivierungszwecken ausgedruckt wird.
Der PDF-Export wurde auf Wunsch der kooperierenden Pflegeeinrichtungen implementiert, da es sonst keine Möglichkeit gibt, die eingetragenen Patientendaten menschenlesbar zu speichern. Der XML-Export ist zwar standardkonform und interoperabel, kann aber nicht sinnvoll in Papierform archiviert werden. Es ist klar, dass der PDF-Export für die voranschreitende Digitalisierung und Standardisierung im Gesundheitswesen nicht zielführend ist. Dennoch wird der PDF-Export als Übergangsfeature nötig sein, da Pflegeheime, deren Prozesse auf eine papierbasierte Dokumentation ausgerichtet sind, in der Umstellungsphase weiterhin die Möglichkeit haben müssen, der gesetzlichen Dokumentationspflicht nachzukommen. Die XML-Datei (= PIO-ULB) auszudrucken, ist hierbei keine Option.
1.12 Wie funktioniert die Validierung von XML-Dateien?
Wenn der Nutzer eine XML-Datei in unseren PIO-ULB Editor importiert, wird automatisch eine Validierung der XML-Struktur gestartet. Die Validierung geschieht offline anhand von FHIR Strukturdefinitionen. Diese Strukturdefinitionen beschreiben genau, wie die XML-Datei strukturiert sein muss und welche Werte gültig sind. Die Strukturdefinitionen für den PIO-ULB wurden hier [Stand 28.01.2025] heruntergeladen. Wenn eine XML-Datei importiert wird, ist in der Menüzeile der Status der Validierung ersichtlich (siehe Abbildung). Die Validierung benötigt ca. 20 Sekunden.

Abbildung: Menüzeile des PIO-ULB Editors mit laufendem Validierungsprozess (Ladesymbol links)
Sobald die Validierung abgeschlossen ist, ändert sich das Ladesymbol in eines der folgenden Symbole je nach Validierungsergebnis:

Abbildung: Symbole für unterschiedliche Validierungsergebnisse (links: Fehler vorhanden, mitte: Warnungen vorhanden, rechts: Validierung erfolgreich)
Durch einen Klick auf das Symbol öffnet sich ein Popup-Fenster mit genaueren Informationen zum Validierungsergebnis. Dieses Popup zeigt das Ergebnis sowie die Anzahl der gefundenen Fehler und Warnungen. Weiterhin sind detaillierte Informationen zu jedem Fehler und jeder Warnung einsehbar, indem man die entsprechenden Felder am unteren Ende des Popups ausklappt (siehe Abbildung). Die detaillierten Informationen sind nicht für Pflegefachpersonen, sondern für den technischen Support gedacht.
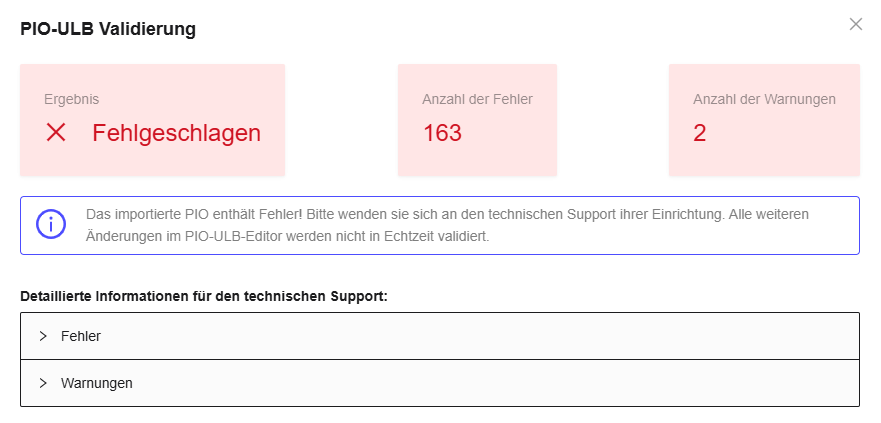
Abbildung: Fehlgeschlagene Validierung mit 163 Fehlern und 2 Warnungen
Die Validierung der XML-Datei wird einmalig mit dessen Import angestoßen. Alle weiteren Änderungen, die der Nutzer im Editor vornimmt, werden nicht in Echtzeit validiert. Die Validierungsfunktion ist als extra Feature zu verstehen, welches nicht für das Pflegepersonal gedacht ist, sondern für technisches Personal. Ist eine PIO-ULB Datei, die von einer anderen Einrichtung geschickt wurde, beschädigt, kann der Validator ein nützliches Tool sein, um den Fehler in der Datei zu finden.
Sollte die importierte Datei vom PIO-ULB Editor nicht geöffnet werden können (weil z.B. ein Textdokument ohne XML-Tags oder ein XML-Dokument mit falschem Root-Tag importiert wurde), wird automatisch der Validator gestartet, um dem Nutzer Feedback zu geben, warum die Datei nicht geöffnet werden kann. Ein weiterer Fehlerfall, der erwähnenswert ist, stellt die inkonsequente Verwendung von XML-Tags im PIO-ULB dar. Fehlt z.B. ein XML-Closing-Tag, so kann der Editor zwar die XML-Datei öffnen, alle Daten unterhalb der Fehlerstelle werden jedoch nicht angezeigt. Es fehlen also wichtige medizinische Daten. Um auf die fehlenden Daten aufmerksam zu machen, öffnet sich in diesem speziellen Fall das Validierungs-Popup-Fenster automatisch und zeigt folgenden Fehler an:

Abbildung: Fehlgeschlagene Validierung aufgrund strukturellem Fehler der XML-Tags
1.13 Gibt es eine Bedienungsanleitung für den PIO-ULB Editor?
Ja, wir haben eine eigene Bedienungsanleitung für den PIO-ULB Editor geschrieben. Die Anleitung ist hier zu finden:
1.14 Welche Veröffentlichungen gab es im Rahmen des Forschungsprojektes Care Regio?
Folgende Tabelle listet alle Veröffentlichen auf, die im Rahmen des Forschungsprojektes Care Regio erarbeitet wurden. Unter 3.10 ist außerdem eine umfangreiche Softwaredokumentation des PIO-ULB Editors nach dem Arc42 Standard zu finden.
2. Strukturelle Fragen zum PIO-ULB Standard:
2.1 Wo finde ich Informationen zum PIO-ULB Standard?
Die mio42 GmbH (Entwickler des PIO-ULB Standards) veröffentlichen alle Informationen bezüglich der MIOs und PIOs auf dieser Website:
Infos zum PIO-ULB Standard [Stand: 16.04.2025]
Speziell für den Überleitungsbogen finden sich hier ein Informationsmodell, welches den Inhalt des PIO-ULBs fachlich darstellt, und eine Auflistung aller FHIR Profile, also eine technische Darstellung aller Inhalte (mehr Infos siehe 2.2).
Alle Informationen über die FHIR Profile und den genauen Aufbau der XML-Datei (= PIO-ULB) findet man auf simplifier:
Simplifier PIO-ULB [Stand: 16.04.2025]
Simplifier ist eine Website, auf der FHIR basierte Projekte veröffentlicht werden können. Auch der Überleitungsbogen wurde hier veröffentlicht. Wir empfehlen simplifier für die technische Einarbeitung in den PIO-ULB Standard zu verwenden, da hier die XML-Struktur verständlicher nachgebildet wird. Die FAQs beziehen sich auf die zurzeit aktuellste Version der PIO-ULB Spezifikation, nämlich die Version 1.0.0.
Weiterhin hat die mio42 GmbH unseren PIO-ULB Editor als offizielles Referenzprojekt auf der MIO-Plattform verlinkt. [Stand 16.04.2025]
Weiterführende Informationen:
- Festlegung des PIO-ULB Standards als PDF-Dokument [Stand 16.04.2025]
2.2 Wie funktioniert das ressourcenbasierte Konzept von FHIR?
FHIR (Fast Healthcare Interoperability Resources) ist ein international anerkannter Standard zur Abbildung von Gesundheitsdaten. FHIR bietet so viele Freiheiten, dass der Standard leicht an nationale Gegebenheiten und anwendungsspezifische Kontexte angepasst werden kann. Alle MIOs und PIOs werden als FHIR Projekt umgesetzt.
FHIR unterscheidet folgende Begrifflichkeiten:
- Ressourcen
- Profile
- Profil-Instanzen
Ressourcen sind Strukturen, die vom FHIR Standard vorgegeben werden. Zum Beispiel definiert die Patient-Ressource, in welcher Struktur Patientendaten abzubilden sind. Die Observation-Ressource gibt die Datenstruktur von Messungen oder einfachen Beobachtungen eines Patienten, eines Gerätes oder eines anderen Objektes vor. Die Procedure-Ressource definiert wiederum die Struktur einer Aktion, die an einem Patienten ausgeführt wird oder wurde.
Profile werden von den Ressourcen abgeleitet und sind ebenfalls Strukturen, die vorgeben, in welcher Form Patientendaten gespeichert werden sollen. Diese Strukturen sind jedoch an einen speziellen Anwendungskontext angepasst und entstehen durch das Beschränken oder Ergänzen von Elementen der Ressource. So hat die mio42 GmbH zum Beispiel die Patienten-Ressource an den Überleitungskontext angepasst und das Profil KBV_PR_MIO_ULB_Patient erstellt. Weiterhin beschreibt das Profil KBV_PR_MIO_ULB_Observation_Heart_Rate die Messung der Herzfrequenz und das Profil KBV_PR_MIO_ULB_Procedure_Nursing_Measures eine Pflegemaßnahme im Überleitungskontext.
Profil-Instanzen sind Profile, die mit realen Daten befüllt sind. Wenn also das Profil KBV_PR_MIO_ULB_Observation_Heart_Rate mit einem Wert für die Herzfrequenz versehen wird, ist aus einer reinen Beschreibung der Datenstruktur eine Profil-Instanz geworden. Profil-Instanzen sind immer mit einer eindeutigen ID gekennzeichnet.
Der Aufbau eines FHIR-Datensatzes:
Ein FHIR-Datensatz (z.B. ein PIO-Überleitungsbogen) besteht aus vielen verschiedenen Profil-Instanzen, die mit realen Patientendaten befüllt sind und als einzelne Bausteine für den gesamten Datensatz dienen. Für den PIO-ULB wurden viele Profile definiert, die behandelnde Personen (z.B. Hausärzte oder Pflegepersonal), Diagnosen, Vitalwerte, Patientenstammdaten, Kontaktpersonen, Bevollmächtigungen, Medikamente, usw. abbilden. Werden diese Profile instanziiert und mit Daten befüllt, stellen sie in ihrer Gesamtheit einen PIO-ULB (also einen FHIR-Datensatz) dar. Jede Profil-Instanz bzw. jeder Baustein in einem FHIR-Datensatz ist mit einer eindeutigen ID (z.B. UUID) versehen.
2.3 Aus wie vielen Profilen besteht der PIO-ULB Standard?
Der PIO-ULB Standard besteht laut simplifier aus 91 Profilen:
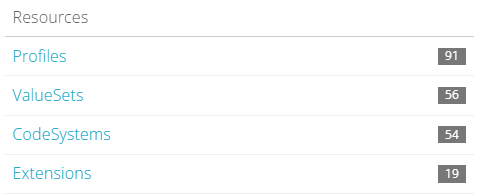
Abbildung: Simplifier zeigt, dass der PIO-ULB Standrad aus 91 Profilen besteht
Bei genauerem Hinsehen bemerkt man, dass eines der Profile (KBV_PR_MIO_ULB_Identifier_PKV_KVID_10) nicht als eigenständige Profil-Instanz abgeleitet werden kann, da der Identifier nur zur Abbildung einer 10-stelligen Versicherten-ID innerhalb des Profils “KBV_PR_MIO_ULB_Patient” verwendet wird:

Abbildung: Das Identifier_PKV_KVID_10 Profil innerhalb des Patienten-Profils af simplifier
Daher besteht die PIO-ULB Spezifikation unserer Auffassung nach aus 90 instanziierbaren Profilen bzw. aus 90 Bausteinen, die dann zu einem FHIR-Bundle (also eine FHIR-Datensatz) zusammengesetzt werden können.
2.4 Welcher Dateityp ist für ein PIO-ULB vorgesehen?
Laut FHIR können Datensätze als XML- oder JSON-Datei erstellt werden. Die mio42 GmbH spezifizierte jedoch, dass alle MIOs und PIOs als XML-Datei gespeichert werden müssen.
Quelle:
- Dateiformat von MIOs und PIOs [Stand 16.04.2025]
2.5 Welche Besonderheiten gelten für das Bundle- und Composition-Profil?
Die Profile “KBV_PR_MIO_ULB_Bundle“ und “KBV_PR_MIO_ULB_Composition“ sind besondere Profile, während alle anderen nur als Informationsbausteine dienen. Diese zwei Profile müssen verpflichtend in einem PIO-ULB instanziiert werden.
Composition:
Jede Profil-Instanz bzw. jeder Informationsbaustein in einem FHIR-Datensatz ist mit einer eindeutigen ID (z.B. UUID) versehen. Die Composition ist eine Art Inhaltsverzeichnis, welche alle IDs von jeder im Datensatz vorkommenden Profil-Instanz direkt oder indirekt referenziert. Zusätzlich beinhaltet die Composition Informationen wie Erstellungsdatum, Informationen zum Autor und die empfangende Einrichtung.
Bundle:
Das Bundle ist das alles umfassende FHIR Profil. Es beinhaltet alle anderen Profil-Instanzen (inkl. Composition). Der XML-Root-Tag eines PIO-ULBs ist also <Bundle>. Außerdem beinhaltet das Bundle einen Zeitstempel.
Weiterführende Informationen:
- Erklärung von "Composition" und "Bundle" der mio42 GmbH [Stand 16.04.2025]
- FHIR-Struktur des Bundles auf simplifier [Stand 16.04.2025]
- FHIR-Struktur der Composition auf simplifier [Stand 16.04.2025]
2.6 Aus welchen Profilen bzw. Informationen muss ein PIO-ULB mindestens bestehen?
Die Kardinalitäten (also wie oft ein bestimmtes Element minimal bzw. maximal vorkommen darf) sind für das gesamte PIO-ULB auf folgender Seite abgebildet:
Auflistung aller PIO-ULB Elemente inkl. Kardinalitäten [Stand: 16.04.2025]
Nach längerem Studieren der umfangreichen Tabelle stellt man fest, dass folgende Profil-Instanzen mindestens im PIO-ULB enthalten sein müssen. Die Unterpunkte zu jedem Profil geben an, welche Informationen in dem jeweiligen Profil verpflichtend angegeben werden müssen:
- KBV_PR_MIO_ULB_Bundle
- Zeitstempel
- KBV_PR_MIO_ULB_Composition
- Erstellungsdatum der Composition
- Referenz auf den Autor (Organization-, Practitioner- oder PractitionerRole-Profil-Instanzen)
- KBV_PR_MIO_ULB_Organization oder KBV_PR_MIO_ULB_Practitioner oder KBV_PR_MIO_ULB_PractitionerRole (als Autor des PIO-ULBs)
- Name des Autors*
- KBV_PR_MIO_ULB_Patient
- Patientenname*
- Geburtsdatum*
- KBV_PR_MIO_ULB_Observation_Care_Level
- Antragsstatus des Pflegegrads*
- KBV_PR_MIO_ULB_Observation_Presence_Problems
- Vorhandensein von med. Diagnosen (KBV_PR_MIO_ULB_Condition_Medical_Problem_Diagnosis) und pfleg. Nebendiagnosen (KBV_PR_MIO_ULB_Condition_Care_Problem) anhand der Auswahlmöglichkeiten (ja / nein / unbekannt*)
- KBV_PR_MIO_ULB_Observation_Presence_Risks
- Vorhandensein von Risiken (KBV_PR_MIO_ULB_Observation_Risk) anhand der Auswahlmöglichkeiten (ja / nein / unbekannt*)
- KBV_PR_MIO_ULB_Observation_Presence_Information_Nutrition
- Vorhandensein von einer der drei Profil-Instanzen (KBV_PR_MIO_ULB_Observation_Food_Type, KBV_PR_MIO_ULB_Observation_Food_Administration_Form, KBV_PR_MIO_ULB_Observation_Nutrition) anhand der Auswahlmöglichkeiten (ja / nein / unbekannt*)
- KBV_PR_MIO_ULB_Observation_Isolation_Necessary
- Vorhandensein von Isolationsangaben (KBV_PR_MIO_ULB_Procedure_Isolation) anhand der Auswahlmöglichkeiten (ja / nein / unbekannt*)
- KBV_PR_MIO_ULB_Observation_Presence_Functional_Assessment
- Vorhandensein von einer der drei Profil-Instanzen (KBV_PR_MIO_ULB_Observation_Total_Barthel_Index, KBV_PR_MIO_ULB_ClinicalImpression_Individual_Functions_Barthel, KBV_PR_MIO_ULB_Observation_Assessment_Free) anhand der Auswahlmöglichkeiten (ja / nein / unbekannt*)
- KBV_PR_MIO_ULB_Observation_Presence_Allergies
- Vorhandensein von Allergien (KBV_PR_MIO_ULB_AllergyIntolerance) anhand der Auswahlmöglichkeiten (ja / nein / unbekannt*)
- KBV_PR_MIO_ULB_Observation_Degree_Of_Disability_Available
- Vorhandensein von einem Grad der Behinderung (KBV_PR_MIO_ULB_Observation_Degree_Of_Disability) anhand der Auswahlmöglichkeiten (ja / nein / unbekannt*)
Alle mit * markierten Angaben müssen vom Nutzer aktiv eingegeben werden, alle anderen Angaben können automatisch generiert werden. Das heißt, ein Editor, der den PIO-ULB Standard abbildet, muss mindestens für die markierten (*) Informationen ein Eingabefeld bereitstellen.
Die Profile, die lediglich das Vorhandensein von anderen Profil-Instanzen abbilden, werden verwendet, um z.B. alle Allergien (für jede einzelne Allergie des Patienten gibt es ja eine eigene Profil-Instanz) zu bündeln. Das Profil KBV_PR_MIO_ULB_Observation_Presence_Allergies referenziert zum Beispiel alle Allergie-Profil-Instanzen (hält also deren IDs) und bündelt sie somit. Nun muss im Inhaltsverzeichnis (Composition) nicht mehr jede einzelne Allergie-Profil-Instanz referenziert werden, sondern lediglich die ID der Profil-Instanz des Profils KBV_PR_MIO_ULB_Observation_Presence_Allergies angegeben werden. Ein weiterer Vorteil ist, dass dieses “Bündel-Profil” zwischen “Nein, der Patient hat keine Allergien“ und “Es ist unbekannt, ob der Patient Allergien hat“ unterscheiden. Diese Differenzierung ist im pflegerischen Fachgebiet ein wichtiges Detail.
Im Fall eines PIO-ULBs mit minimalem Umfang müssen diese “Bündel-Profil-Instanzen” zwar existieren, deren Inhalt lautet dann aber einfach: “Nein, es gibt keine Allergien” etc.!
Weiterführende Informationen:
- Struktur des Allergie-Profils auf simplifier [Stand 16.04.2025]
- Struktur des Presence-Allergie-Profils auf simplifier [Stand 16.04.2025]
2.7 Gibt es Beispiel-Dateien, die ein vollständiges PIO-ULB abbilden?
Ja, gibt es. Die mio42 GmbH hat zwei Fallbeispiele auf ihrer Internetseite veröffentlicht:
Fallbeispiele der mio42 GmbH [Stand: 16.04.2025]
Weiterhin ist es möglich mit unserem PIO-ULB Editor eigene PIO-ULBs zu erstellen. Im Hauptmenü des PIO-ULB Editors kann ein Demo-PIO geöffnet werden (siehe Abbildung), welches einen schnellen Export eines vollständigen1 PIO-ULBs ermöglicht, ohne alle Eingabefelder selbst ausfüllen zu müssen.
Abbildung: Ausschnitt aus dem Hauptmenü des PIO-ULB Editors (Button "Demo öffnen" erstellt ein voll ausgefülltes PIO-ULB)
1 Achtung: Unser PIO-ULB Editor unterstützt nur zwei Drittel der gesamten PIO-ULB Spezifikation (siehe 1.7)
2.8 Was ist eine “extension” in FHIR?
Eine extension ist ein Element von FHIR, mit welchem FHIR Ressourcen erweitert werden können. Durch das Beschränken oder Erweitern von FHIR Ressourcen entstehen Profile (siehe 2.2). Dies ermöglicht es, den internationalen Standard an nationale Kontexte anzupassen. Zum Beispiel wurde für die PIO-ULB Spezifikation die Patienten-Ressource durch drei weitere Informationen erweitert (siehe Abbildung), wodurch das Profil KBV_PR_MIO_ULB_Patient entstanden ist.

Abbildung: Patienten-Ressource des PIO-ULB Standards um drei extensions erweitert
Quelle:
- Patienten-Profil auf simplifier [Stand 16.04.2025]
2.9 Welche FHIR-Ressourcen bzw. Basis-Profile werden im PIO-ULB verwendet?
Da die mio42 GmbH und die Kassenärztliche Bundesvereinigung (KBV) viele MIOs und PIOs entwickeln, macht es Sinn, ein Basis-Set an Profilen zu entwickeln und diese immer wieder zu verwenden. Zum Beispiel stellt das FHIR-Core Package eine Ressource bereit, die eine Kontaktperson abbildet:

Abbildung: Kontaktperson-Ressource aus dem Core Package des FHIR-Standards
Die KBV hat dann auf dessen Basis ein eigenes Profil zur Abbildung einer Kontaktperson erstellt. Dieses Profil gehört zu den KBV-Basisprofilen, was an dem Namen erkenntlich ist (KBV_PR_Base_RelatedPerson):

Abbildung: Kontaktperson-Profil als Basisprofil der KBV
Die mio42 GmbH hat nun für das spezielle Projekt PIO-Überleitungsbogen wiederum ein eigenes Profil erstellt, das von dem KBV-Basisprofil abgeleitet wurde:
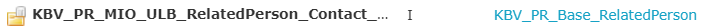
Abbildung: Kontaktperson-Profil der PIO-ULB Spezifikation
Nun stellt sich die Frage, welche FHIR-Ressourcen bzw. Basis-Profile für den PIO-ULB verwendet wurden? Das PackageManifest auf simplifier liefert die Antwort (siehe Abbildungen):
Abbildung: Link zum PackageManifest auf simplifier

Abbildung: Das PackageManifest der PIO-ULB Spezifikation im JSON Format (Verwendung von drei Packages unter dem Key "dependencies")
Man sieht, dass für den PIO-ULB KBV-Basisprofile ("kbv.basis"), deutsche Basisprofile ("de.basisprofil.r4") und die FHIR Core Ressourcen ("hl7.fhir.r4.core") in verschiedenen Versionen verwendet werden.
Quellen:
- Kontaktperson-Ressource aus dem FHIR-Core Package auf simplifier [Stand 16.04.2025]
- Kontaktperson-Profil aus dem KBV-Basis Package auf simplifier [Stand 16.04.2025]
- Kontaktperson-Profil aus dem PIO-ULB Standard auf simplifier [Stand 16.04.2025]
- PackageManifest des PIO-ULB Standards auf simplifier [Stand 16.04.2025]
2.10 Wie ist eine Profil-Instanz strukturell aufgebaut?
Das Allergie-Profil soll als Beispiel dienen und ist unter folgendem Link zu finden:
Allergie-Profil der PIO-ULB Spezifikation auf simplifier [Stand: 16.04.2025]

Abbildung: Erste Hierarchieebene des Allergie-Profils aus der PIO-ULB Spezifikation auf simplifier
Simplifier stellt die Profile mithilfe einer aufklappbaren hierarchischen Struktur dar, welche die Schachtelung der XML-Tags eins zu eins widerspiegelt. Für jedes Element sind Kardinalitäten (z.B. 0..*) angegeben. "Must support" Elemente sind mit einem roten "S" gekennzeichnet. Im Folgenden soll der Aufbau des Allergie-Profils und einer zugehörigen Profil-Instanz genauer erklärt werden:
Der Header:
Der Header ist in jedem Profil der PIO-ULB Spezifikation identisch aufgebaut. Der Begriff "Header" wurde von uns eingeführt und ist keine offizielle FHIR-Bezeichnung. Dennoch fanden wir den Begriff passend. Im Header sind die ID der Profil-Instanz (in diesem Fall eine UUID) und die Art des Profils (siehe "profile") hinterlegt:

Abbildung: Header des Allergie-Profils auf simplifier

Abbildung: Header einer Allergie-Profil-Instanz als XML-Repräsentation
Der XML-Tag <id> ist auf simplifier nicht sichtbar, ist aber für jede FHIR Profil-Instanz verpflichtend. <id> wird von einer FHIR-Basisressource vererbt.
Binding und Pattern Symbole:
Simplifier verwendet folgende “Binding”- und “Pattern”-Symbole:

Abbildung: "Binding" und "Pattern" Symbole auf simplifier
“Binding” bedeutet, dass der Wert an ein Codesystem gebunden ist, während “Pattern” einen fixen Wert vorgibt, für den keine Nutzereingabe erforderlich ist.
Extension:
Nähere Informationen zu <extension> gibt es unter 2.8. Die Repräsentation einer <extension> in der XML-Datei sieht wie folgt aus:

Abbildung: Extension im Allergie-Profil auf simplifier (am Beispiel "abatement")

Abbildung: Extension einer Allergie-Profil-Instanz als XML-Repräsentation (am Beispiel "abatement")
CodeableConcept:
Oft werden codierte Informationen als CodeableConcept abgebildet. Beim Allergie-Profil wird z.B. der Verifikationsstatus mit einem CodeableConcept codiert. CodeableConcepts sind immer identisch aufgebaut und an ein spezielles Codesystem gebunden (siehe Binding-Symbol in der Abbildung). Ein CodeableConcept ist wie folgt aufgebaut:

Abbildung: Verifikationsstatus des Allergie-Profils als CodeableConcept auf simplifier

Abbildung: Verifikationsstatus einer Allergie-Profil-Instanz als XML-Repräsentation (als CodeableConcept)
Codierung des Allergie-Codes mittels Slice-Element:
Auch der Code der Allergie ist als CodeableConcept repräsentiert.

Abbildung: Allergie-Code des Allergie-Profils auf simplifier (als CodeableConcept)
Neu ist hier das blaue Slice-Element, welches dem Nutzer in diesem Fall die Freiheit gibt, die Allergie mittels SNOMED-CT oder ASK Code anzugeben. Die PIO-ULB Spezifikation lässt an dieser Stelle also zwei verschiedene Codesysteme zu. Unser PIO-ULB Editor unterstützt jedoch nur SNOMED-CT Codes.
Außerdem sieht man, dass ein CodeableConcept ein <text> Element besitzen kann. Dieses Element dient der Freitextbeschreibung des Codes. Der Nutzer hat also auch die Möglichkeit, keinen Code anzugeben, und die Allergie mit einem Freitext zu benennen. Die XML-Repräsentation könnte dann wie folgt aussehen:

Abbildung: Allergie-Code einer Allergie-Profil-Instanz als XML-Repräsentation (als CodeableConcept)
Referenzen auf andere Profil-Instanzen:
Jede Profil-Instanz ist mithilfe einer ID (z.B. UUID) innerhalb eines PIO-ULBs eindeutig identifizierbar. Diese ID kann verwendet werden, um von einer Profil-Instanz auf eine andere zu referenzieren. Im Fall der Allergie kann der Diagnosesteller referenziert werden. Dies kann der Patient selbst sein oder ein Hausarzt bzw. behandelnde Person (= Practitioner).
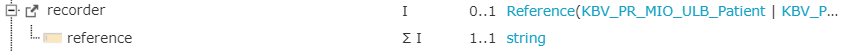
Abbildung: Referenz auf den Diagnosesteller des Allergie-Profils auf simplifier

Abbildung: Referenz auf den Diagnosesteller einer Allergie-Profil-Instanz als XML-Repräsentation
2.11 Welche Codesysteme werden im PIO-ULB verwendet?
Für den PIO-ULB werden verschiedene Terminologien verwendet. Das bevorzugte Codesystem ist SNOMED-CT, es kommen aber weitere Codesysteme zum Einsatz wie z.B. LOINC, ICD-10, ATC, Alpha-ID. Alle verwendeten Codesysteme sind hier aufgelistet:
Verwendete Code Systeme im PIO-ULB (Auflistung der mio42 GmbH) [Stand: 16.04.2025]
Unser PIO-ULB Editor unterstützt jedoch nur SNOMED-CT Codes. Sollte ein PIO-ULB importiert werden, welches andere Terminologien nutzt, kann unser Editor diese trotzdem anzeigen (siehe Abbildung, “Turkish”):
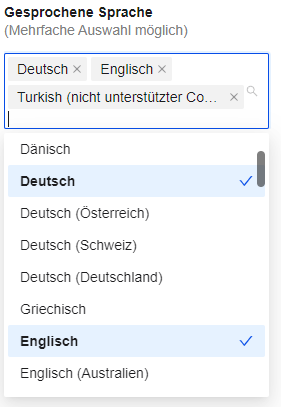
Abbildung: Ausschnitt aus dem Demo-PIO des PIO-ULB Editors, in dem ein nicht unterstützter Code ("Turkish") verwendet wird
Entsprechende Codes werden mit dem Vermerk (nicht unterstützter Code) versehen. Der Nutzer kann diesen Code lesen und auch wieder exportieren. Wurde der Code jedoch gelöscht, kann er nicht erneute aus dem Drop Down ausgewählt werden.
Folgende Liste enthält die URLs zu allen Codesystemen, die wir für unseren PIO-ULB Editor heruntergeladen haben (also nur SNOMED-CT Codesysteme):
2.12 Wo finde ich deutsche Übersetzungen für die Codes, die im PIO-ULB verwendet werden?
Leider existieren die meisten SNOMED-CT Codes aktuell nur auf Englisch. Es wird gerade an einer deutschen Übersetzung gearbeitet. An welchen Übersetzungen gerade gearbeitet wird, ist auf folgender Seite ersichtlich:
Bundesinstitut für Arzneimittel und Medizinprodukte: Deutsche Übersetzungen von SNOMED-CT-Konzepten [Stand: 16.04.2025]
Da nur das Bundesinstitut für Arzneimittel und Medizinprodukte (BfArM) deutsche Übersetzungen von SNOMED-CT Codes veröffentlichen darf, hat die mio42 GmbH einen Umweg gewählt, um kleinere Codesysteme zu “übersetzen”. Um nicht von einer “Übersetzung” sprechen zu müssen, verwendet die mio42 GmbH sogenannte ConceptMaps. ConceptMaps stammen aus dem FHIR-Standard und mappen die originalen Codes auf eine deutsche Repräsentation.
Abbildung: Link zur ConceptMap der PIO-ULB Spezifikation auf simplifier
Weiterführende Informationen:
- ConceptMap der PIO-ULB Spezifikation auf simplifier [Stand 16.04.2025]
- ConceptMap des KBV-Basis Packages auf simplifier [Stand 16.04.2025]
2.13 Wie funktionieren Referenzen innerhalb eines PIO-ULBs?
Jede Profil-Instanz ist mithilfe einer ID innerhalb eines PIO-ULBs eindeutig identifizierbar. Diese ID kann verwendet werden, um von einer Profil-Instanz auf eine andere zu referenzieren. Im PIO-ULB Editor werden UUIDs als ID verwendet, weil die mio42 GmbH in ihren Beispiel PIO-ULBs (siehe 2.7) ebenfalls UUIDs verwendet hat. Ein Beispiel für eine Referenzierung befindet sich unter 2.10.
2.14 Wird es in Zukunft Änderungen an dem Standard geben?
Der PIO-ULB Standard wurde im Dezember 2022 als Version 1.0.0 festgelegt. Eine Änderung der Spezifikation halten wir für wahrscheinlich. Dies kann im Rahmen von sogenannten "Fortschreibungen" passieren. Die Änderungen sollten sich aber auf kleine Anpassungen beschränken. Dies wird aber nicht in naher Zukunft passieren, da das PIO-ULB aufgrund neuer Gesetze des Deutschen Bundes den Fokus verloren hat. Andere MIOs haben aktuell höhere Priorität wie der PIO-ULB. Der genaue Zeitpunkt von PIO-ULB Fortschreibungen ist aktuell noch unklar.
Simplifier besitzt einen Änderungs-Log, in dem alle Veränderungen an dem Projekt dokumentiert werden.
Änderungs-Log des PIO-ULB Projektes auf simplifier [Stand: 16.04.2025]
2.15 Wie weit ist der PIO-ULB Standard bisher verbreitet?
Der PIO-ULB Standard ist bisher leider nicht weit verbreitet. Ein Ziel der mio42 GmbH ist es, die flächendeckende Erprobung des PIO Überleitungsbogen zu unterstützen, allerdings haben sie dafür keinen offiziellen Auftrag. Unser Forschungsprojekt Care-Regio leistet somit Pionierarbeit bei der Umsetzung und Erprobung des neuen PIO-ULB Standards.
Uns sind keine Hersteller von medizinischen und pflegerischen Dokumentationssystem bekannt, die den PIO-ULB Standard verkaufsfertig implementiert haben. Die C&S Computer und Software GmbH in Augsburg haben den PIO-ULB zwar bereits implementiert, sind aber noch nicht marktreif. Weiterhin sind wir mit der ZiemannIT aus München in Kontakt, um bei der ersten beispielhaften Implementierung einiger weniger FHIR Profilen beratend zu unterstützen.
3. Technische Fragen zur Softwarearchitektur des PIO-ULB Editors:
3.1 In welchen Systemkontext ist der PIO-ULB Editor einzuordnen?
Unser PIO-ULB Editor ist wie folgt in den Systemkontext einzuordnen:
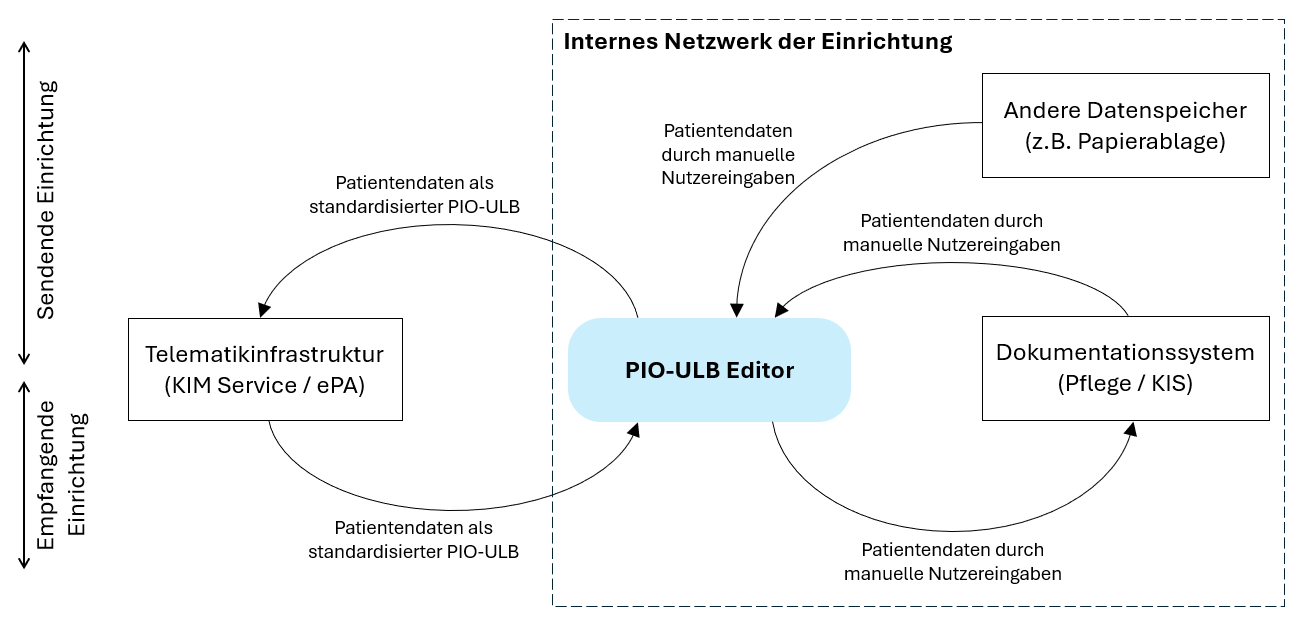
Abbildung: UML-Kontext-Diagramm des PIO-ULB Editors
Vor der Patientenüberleitung befinden sich die Patientendaten in unterschiedlichen Formen im Verwaltungsapparat der entsendenden Einrichtung und müssen letztendlich in das System der aufnehmenden Einrichtung übertragen werden. Im Fall eines Pflegeheimes werden pflegerische Dokumentationssysteme verwendet, im Krankenhaus speichert das Krankenhausinformationssystem (KIS) die Patientendaten. Der PIO-ULB Editor muss aus datenschutzrechtlichen Gründen im internen Netzwerk der Einrichtung laufen, welche die Patientendaten verarbeitet. Soll der Editor im lokalen Netzwerk der Einrichtungen laufen, ist hierfür die „localVersion“ vorgesehen (siehe 3.4).
Der Prozess in der entsendenden Einrichtung wird durch die oberen Pfeile in der Abbildung dargestellt. Eine Pflegefachperson muss alle Patientendaten (evtl. aus verschiedenen Quellen) sammeln und manuell in den PIO-ULB Editor eintragen. Die aus dem Editor exportierte XML-Datei (= PIO-ULB) kann entweder in die elektronische Patientenakte (ePA) hochgeladen oder mittels KIM-Service (Kommunikation im Medizinwesen) versendet werden. Beides sind Services der Telematikinfrastruktur (TI). Die TI ist als deutsches Gesundheitsnetzwerk zu verstehen, über welches sensible Patientendaten datenschutzkonform versendet und gespeichert werden können. Im Rahmen des Forschungsprojektes wurden die PIO-ULBs über den KIM-Service versendet.
Der komplementäre Prozess in der aufnehmenden Einrichtung wird durch die unteren Pfeile in der Abbildung dargestellt. Die aufnehmende Einrichtung erhält den PIO-ULB in Form einer KIM-Nachricht. Alternativ kann der PIO-ULB auch aus der ePA heruntergeladen werden, nachdem der Patient entsprechende Zugriffsberechtigungen erteilt hat. Der PIO-ULB wird nun in den Editor importiert. Die visualisierten Daten können jetzt manuell in das Dokumentationssystem der aufnehmenden Einrichtung übertragen werden.
3.2 Aus welchen Komponenten besteht der PIO-ULB Editor?
Unser PIO-ULB Editor besteht aus folgenden Komponenten:
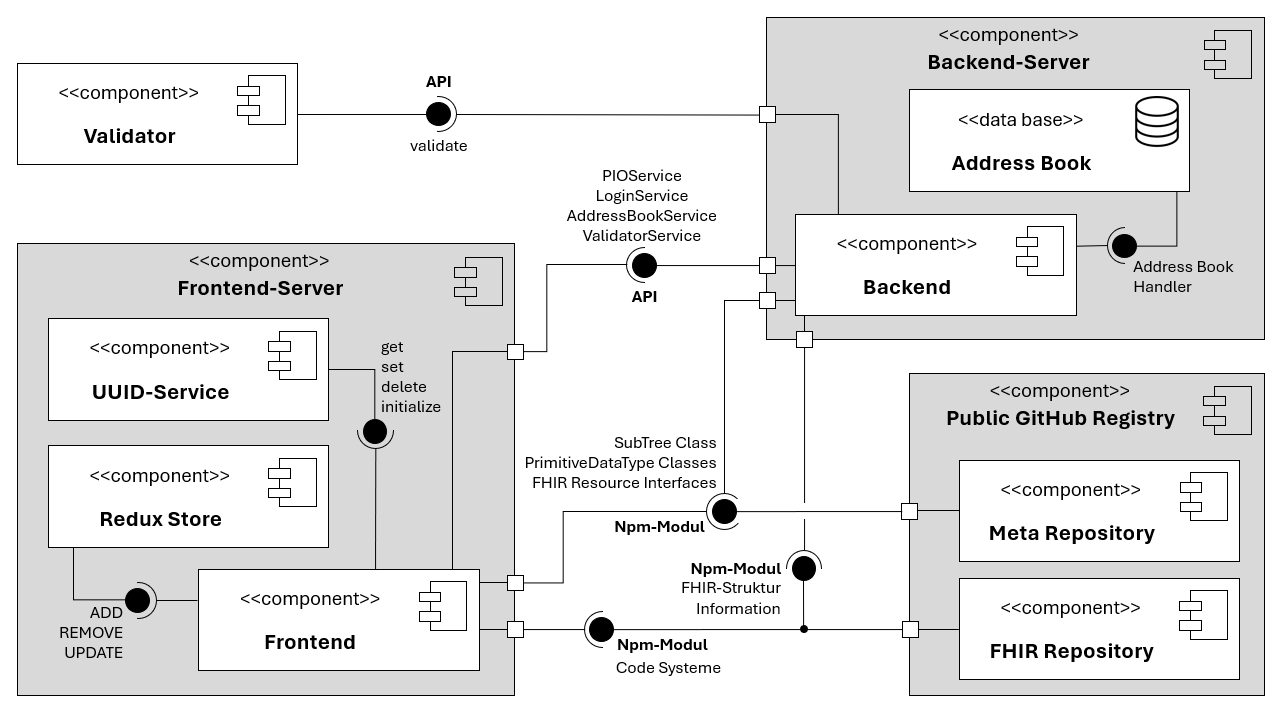
Abbildung: UML-Komponenten-Diagramm des PIO-ULB Editors
Der Backend-Server ermöglicht es mehreren Nutzern gleichzeitig, PIOs zu bearbeiten, insofern jeder Nutzer über ein eigenes Frontend angemeldet ist. Sobald die Nutzer ihren Vor- und Nachnamen eingegeben haben, erstellt der „AnmeldeService“ eine neue Session. Die Eingabe eines Passwortes ist nicht nötig, da der Editor keine interne Nutzerverwaltung anbietet. Der Nutzername wird im PIO automatisch als Autor hinterlegt. Weiterhin stellt das Backend Logik zum Importieren und Exportieren von XML-Dateien bereit. Eine globale serverseitige Datenbank – das Adressbuch – kann FHIR Organisations-Profil-Instanzen permanent speichern, sodass die Nutzer nicht jedes Mal erneut Daten eines bekannten Pflegeheimes oder Krankenhauses eingeben müssen.
Der Frontend-Server ist als React Webanwendung implementiert und kann über den Browser aufgerufen werden. Die Benutzeroberfläche verwendet vorgefertigte Interface-Komponenten aus der „Ant Design“ Bibliothek für die Dateneingabe. Thematisch zusammengehörende Eingabefelder sind zu einem Ant Design Formular zusammengefasst. Dies ermöglicht eine selbstständige Datenverarbeitung durch jedes Formular selbst. Im Hintergrund speichert der UUID-Service alle bereits erstellten FHIR-Profil-Instanzen und deren UUIDs, damit eingegebene Daten stets der richtigen Instanz zugeordnet werden können. Der Redux Store wird als Zustandsspeicher verwendet. Hier sind Nutzer- und Navigationsinformationen sowie Daten, die über mehrere React Komponenten synchron gehalten werden müssen, temporär abgelegt.
Das Meta- und das FHIR-Repository stellen gewisse Dienste zur Verfügung, die in beiden Hauptkomponenten (Front- und Backend) benötigt werden. Während das FHIR Repository Strukturinformationen über den PIO-ULB sowie verwendete Codesysteme bereitstellt, bündelt das Meta-Repository Klassen, Typen und Interfaces, die in beiden Hauptkomponenten benötigt werden.
Die Validator-Komponente kann ein XML-Dokument gegenüber FHIR spezifischen Strukturdefinitionen offline validieren und wird nur vom Frontend angesprochen, wenn eine neue XML-Datei importiert wird. FHIR-Strukturdefinitionen sind XML-Dateien, die den Aufbau eines FHIR-Profils exakt beschreiben.
3.3 Welche Frameworks und Libraries wurden für die Implementierung des PIO-ULB Editors verwendet?
Alle Komponenten sind als JavaScript (nodeJS) Projekt implementiert. Die einzige Ausnahme stellt die Validator-Komponente dar. Sie ist in C-Sharp (.NET) geschrieben.
Das Frontend verwendet unter anderem folgende Libraries:
- Diverse React-Libraries
- Ant Design (für die UI-Komponenten)
- Axios (für die Kommunikation mit dem Backend)
Das Backend verwendet unter anderem folgende Libraries:
- Axios (für die Front-Backend-Kommunikation)
- Express (für die Front-Backend-Kommunikation)
- fast-xml-parser (für das Generieren und Einlesen von XML-Datein)
- xml-formatter (für das Formatieren von XML-Datein)
- lodash (für das einfache Bearbeiten von JSON-Objekten mittels Pfaden in der Punktnotation)
- mongoDB (Datenbank für das Adressbuch)
- jsonwebtoken (für das Session-Management)
Der Validator verwendet das Firely Projekt, welches FHIR Bundles gegenüber Strukturdefinitionen offline validieren kann.
Weiterführende Informationen:
- Dokumentation von Firely [Stand 16.04.2025]
3.4 Wie funktioniert das Session-Management des PIO-ULB Editors?
Je nachdem mit welcher Umgebungsvariable das Front- bzw. Backend gestartet wir, verhält sich das Session-Management unterschiedlich:
- VERSION_ENV=webVersion
- VERSION_ENV=localVersion
Web-Version:
Da unser PIO-ULB Editor, der öffentlich im Internet abrufbar ist (siehe hier), weltweit Nutzern ermöglicht, auf dasselbe Backend zuzugreifen, wird für jede Anmeldung eine separate Session erstellt. Der Nutzer meldet sich durch die Angabe von Vor- und Nachnamen im Editor an. Das heißt, selbst wenn zwei Personen mit demselben Namen zur selben Zeit den Editor nutzen, erstellt das Backend separate Sessions, sodass es zu keinen ungewollten Überscheidungen kommen kann. Meldet sich der Nutzer wieder ab oder schließt das Browserfenster, wir die Session und alle eingegebenen Daten sofort gelöscht.
Local-Version:
Die lokale Version ist für die Nutzung auf lokalen Computern oder in kleinen Netzwerken (z.B. Pflegeheim) gedacht. Meldet sich hier ein Nutzer (mittels Vor- und Nachname) an, wird eine neue Session erstellt. Sollte der Nutzer von anderen Aufgaben im Arbeitsalltag unterbrochen werden oder wird das Browser Fenster aus Versehen geschlossen, bleibt die Session für eine gewisse Zeit geöffnet und die Daten bleiben gespeichert. Meldet sich der Nutzer erneut mit seinem Namen an, öffnet sich seine alte Session und er kann mit der Bearbeitung des PIO-ULBs fortfahren.
Es wurde absichtlich auf eine umfangreiche Nutzerverwaltung (mit Passwort und Username) verzichtet, weil dies die Anforderungen an einen prototypischen Editor übertroffen hätte. Wie die "localVersion" und die "webVersion" auf einem lokalen Computer installiert werden, ist unter Punkt 1.6 zu lesen.
3.5 Wie ist das Backend aufgebaut?
Das Herzstück im Backend ist die Klasse RootObject, welches alle Daten eines PIO-ULBs abbildet. Für jede Session wird eine RootObject-Instanz erzeugt. Ein angemeldeter Nutzer kann also immer nur ein PIO-ULB gleichzeitig erstellen/bearbeiten. Folgende Abbildung zeigt das UML-Klassendiagramm der RootObject Klasse:

Abbildung: UML-Klassendiagramm der RootObject Klasse
Das RootObject speichert alle Header-Daten des FHIR Bundles und der FHIR Composition in einer eigenen Klasse (PIOHeader). Eine andere Klasse (PIOContent) speichert alle weiteren FHIR Profil-Instanzen in einer einzigen großen JSON-Struktur. Diese Struktur wurde extra für das RootObject entwickelt, ähnelt aber sehr stark der Struktur, die später als XML exportiert wird. Weiterhin wurde die Struktur so entwickelt, dass sie möglichst Kompatibel mit der Library “fast-xml-parser“ ist (siehe 3.3).
Die Methode setValue(path: string, data: PrimitiveDataTypes) der PIOContent Klasse ermöglicht das Hinzufügen oder Überschreiben von Daten. Folgender Methodenaufruf würde eine neue Telefonnummer zu einer Kontaktperson hinzufügen:
setValue("31fd1371-7f90-4f47-9ccb-29047dda8f16.KBV_PR_MIO_ULB_RelatedPerson_Contact_Person.telecom[1].value", new StringPIO("0821-234543643"))
Der Pfad (mit der Punktnotation und […]-Arraynotation) kann direkt so von der Library “lodash” verarbeitet werden (siehe 3.3) und beschreibt an welcher Stelle der JSON-Struktur die Daten eingefügt werden sollen. Die Daten selbst werden als PrimitiveDataTypes übergeben. Das Meta-Repository stellt für jeden von FHIR vordefinierten primitiven Datentyp (z.B. code, string, uri, date, etc.) eine entsprechende Klasse bereit (CodePIO, StringPIO, UriPIO, DatePIO, etc.).
Das Backend ist also möglichst generisch implementiert. Das Backend nimmt einfach Daten und Pfade, an denen die Daten gespeichert werden sollen, entgegen, ohne die PIO-ULB Struktur zu validieren.
Das RootObject stellt außerdem zwei Funktionen bereit, mit denen man alle im RootObject gespeicherten Daten in eine valide XML-Datei transformieren kann und umgekehrt:
- toXML(XMLBuilderOptions?: XmlBuilderOptions) : string
- readXML(userData: IUserData, xmlString: string) : RootObject
3.6 Wie ist das Frontend aufgebaut?
Das Frontend definiert Basic-UI-Komponenten (z.B. InputTextField, InputDropDown, etc.), sodass die Eingabefelder über den gesamten PIO-ULB Editor stehts gleich erscheinen.
Diese Basic-UI-Komponenten werden dann in Formularen wiederverwendet. Die Formulare orientieren sich fast ausnahmslos an den FHIR Profilen. Das heißt, dass es für jedes FHIR Profil auch ein entsprechendes Formular gibt (z.B. ContactPersonForm). Jedes Formular hält die für sich relevanten Daten in einem React-State. Bei einem XML-Import initialisieren sich alle Formulare selbständig, indem sie ihre relevanten Daten beim Backend anfragen (die ContactPersonForm holt sich z.B. alle Daten bezüglich der Kontaktpersonen). Editiert der Nutzer ein Eingabefeld wird der lokale State im Formular geupdated, der dann direkt an das Backend übermittelt wird. Nutzereingaben werden also in Echtzeit gespeichert. Die Front-Backend-Kommunikation funktioniert mittels SubTrees (siehe 3.7).
Da das Backend generisch ist, müssen die Formulare selbst die Nutzereingaben an die richtige Stelle in der PIO-ULB Struktur schreiben (mit Hilfe des Pfades, siehe 3.5). Das Wissen über den strukturellen Aufbau eines PIO-ULBs liegt also im Frontend und nicht im Backend.
3.7 Wie kommunizieren Frontend und Backend?
Die Frontend-Formulare holen und senden die Daten in Form von SubTrees an das Backend. SubTrees sind beliebige Ausschnitte aus der Backend-Datenstruktur. Die Formulare können SubTrees auslesen und editieren. Zum Speichern von editierten SubTrees, wird dieser an das Backend geschickt. Dort wird der ausgeschnittene Teil wieder in die Datenstruktur eingefügt.
Mehr zur Front-Backend-Kommunikation unter 3.10.
3.8 Wie funktioniert die Validator-Komponente?
Der Validator ist in C-Sharp (.NET) geschrieben, da das verwendete Projekt (Firely) in C-Sharp geschrieben ist. Firely ermöglicht es, ein FHIR-Bundle gegenüber FHIR-Strukturdefinitionen offline zu validieren. FHIR-Strukturdefinitionen enthalten detaillierte Informationen über den strukturellen Aufbau von FHIR-Profilen oder den Inhalt von Codesystemen.
Die verwendeten FHIR-Strukturdefinitionen sind auf GitHub zu finden (src/Firely.Fhir.Validation.R4/structureDefinitions):
Quellcode des Validators auf GitHub [Stand: 16.04.2025]
Weiterführende Informationen:
- Dokumentation von Firely [Stand 16.04.2025]
3.9 Wie kann ich den PIO-ULB Editor in eine andere (meine eigene) Software integrieren?
Der PIO-ULB Editor ist als Stand-alone Software konzipiert und hat keine offenen Schnittstellen.
Eine Integration des gesamten PIO-ULB Editors kann mittels <iframe> erfolgen. Laufen die Docker-Container auf ihrem System, ist der PIO-ULB Editor unter http://localhost:3000/ erreichbar (siehe 1.6). Folgender Code würde den PIO-ULB Editor dann in einem HTML-Dokument aufrufen:
<iframe src="http://localhost:3000/" width="1500" height="1000" style="border:1px solid">
3.10 Wo finde ich weitere Informationen zur Softwarearchitektur?
Wir haben einen eigenen Artikel bezüglich der Softwarearchitektur des PIO-ULB Editors veröffentlicht. Der Artikel wurde bei der "GMS Medizinische Informatik Biometrie und Epidemiologie 2024" veröffentlicht und kann unter folgendem Link abgerufen werden:
Artikel: Entwicklung eines Editors zur Erstellung und Bearbeitung Pflegerischer Informationsobjekte (PIOs) zur Pflegeüberleitung [Stand 16.04.2025]
Weiterhin haben wir eine sehr umfangreiche Softwaredokumentation nach dem Arc42 Standard geschrieben. Hier ist die Softwarearchitektur des PIO-ULB Editors bis auf Dateiebene heruntergebrochen und genau beschrieben.